
공상하길 좋아하는 AI Research Engineer 입니다.
새로운 지식을 탐구하고 떠오르는 아이디어를 접목해서 속도감 있게 연구하는 것을 좋아합니다.
고객의 마음이 동하도록, 개발될 제품이 헛수고가 되지 않도록, performance · latency · memory 모두 만족시키기 위해 노력합니다.
QAT/PTQ를 통해 edge-device에 들어갈 다양한 model과 inference engine(Pytorch, c++/NDK)을 개발합니다.
-
B1.58-LLM-ASR: B1.58-QAT, Streaming-ASR을 Whisper에서 Decoder-only LLM으로 전환했습니다. google/fleurs에서 WER을 FP16 6.52% → B1.58 6.60%로 0.08%p 이내 차이로 유지했습니다.
-
Efficiency: B1.58 6.60%는 FP16 NVIDIA Nemotron-Streaming-ASR 0.6B(WER 6.20%)와 0.4%p 차이에 불과하지만, ternary weight 기준 약 8× 더 적은 메모리로 동작할 것으로 추정됩니다.
-
Cache-aware streaming: 기존 cache-reset 방식 대신 cache-aware 방식을 도입하여, 항상 일정한 audio·text context를 유지한 채 전사하기 때문에 endless live streaming이나 multi-turn function calling에 유리합니다.
-
B1.58-QAT: whisper-small.en을 ternary weight [-1, 0, 1] QAT(Quantization Aware Training)하여 google/fleurs에서 FP16 6.00% → B1.58 6.38%로 WER 증감을 0.38%p 이내로 억제하였습니다. 자체 개발한 optimium에서 동작시 Synaptics VS680 full-CPU에서 150MB이하 peak memory로 input 9s → output 6.9s 수준의 추론 성능을 확보했습니다. 이는 동일 보드에서 FP16 대비 4× 이상 적은 메모리, 2× 이상 빠른 속도입니다.
-
Streaming-ASR: whisper-small.en에서 streaming ASR을 지원하기 위해 모델 학습부터 kv-cache 관리, read/write policy를 포함한 inference engine까지 end-to-end로 개발하였습니다. B1.58 6.38% → B1.58-streaming 7.28%로 WER 증감 0.9%p가 발생하나, 이제 30s 입력을 기다리지 않고 매 입력 1s chunks 마다 outputs을 내뱉습니다. Synaptics VS680에서 1s chunk당 570ms(RTF 0.57)의 처리 시간으로 실시간 전사가 가능합니다.
-
NPU-CPU: Synaptics VS680에서 whisper-streaming을 Full-CPU → NPU-CPU heterogeneous computing 환경으로 이식 시, 벤더 제공 NPU 블록 수정이 불가하여 발생한 WER 증감(13.77%) 문제를 주변부 layer 재설계로 해결하여 WER 7.41% 까지 복원했으며, full-CPU 대비 추론 속도를 약 1.4× 향상시켰습니다.
-
Live-streaming: 끊임없는 동영상 스트리밍을 가정한 endless-pipeline에 대한 reference implemenation을 개발하였습니다. 긴 전사 과정에서 cache에 담겨있는 audio와 token간 align이 조금씩 틀어지며 cache reset 시점 이후 과도하게 생략되는 부분을 학습 및 policy 수정으로 해결하여 long-form YouTube videos에서 14.05% → 11.92% WER 개선을 달성했습니다.
-
Voice-contral: 기존 성능을 유지하며 특수한 도메인 고유명사에 대한 finetuning, 마이크 노이즈와 주변부 소음에 강건하게 만들기 위한 augmentation 기법을 개발하였습니다.
- B1.58-QAT-SiMT: SiMT(simultaneous machine translation)용 B1.58-QAT 학습부터 streaming kv-cache 관리, read/write policy를 포함한 live-translation용 inference engine까지 end-to-end로 개발하였습니다. Long-form YouTube videos에서 partial chunk 입력에 대한 평균 XCOMET-XXL score 0.8642, AL(Average Lagging) 4.24를 달성하였습니다. Synaptics VS680에서 peak memory ≤50MB · 1-thread, 38 source tokens 평균 600–800ms를 달성하였습니다.
- PR(Punctuation Restoration): STT에서 간혹 구두점이 빠져서 출력되는 현상이나 일상 대화, 인터넷 메신저 채팅등 과 같이 구두점이 없는 source에서 모델이 큰 폭으로 성능이 하락되는 것을 발견하였습니다. 따라서 모델 크기 증감 없이 구두점 복원과 번역을 동시에 수행하는 모델을 개발하였습니다. 그 결과 long-form YouTube 중 구두점이 올바르게 존재하는 영상에서 성능 유지, 구두점이 없는 영상에서 구두점 복원율 precision 0.9988, XCOMET-XXL 0.6581 → 0.9023 으로 크게 증가하였습니다.
- MobileLLM-600M 대상 2-bit uniform weight PTQ(Post Training Quantization) 파이프라인 설계·구현하였습니다.
- A100x1 40GB에서 약 3시간 40분 학습만으로 WikiText2 PPL 8.39(FP16) → 9.59(W2A16, g128)로 열화 1.2 이내를 달성하였습니다.
- TV 음성 제어를 위해 사용자 발화를 받아 intent/slot으로 변환하는 T5 encoder-decoder 기반 single turn function calling 모델을 개발하였습니다. 1500개의 TV제어 관련 발화어 & OOD(Out Of Distribution) 테스트에서 100% 정확도를 달성하였습니다.
- Llama.cpp를 활용하여 T5 encoder-decoder 모델을 셋톱박스(LGU+ UHD4, ARM Cortex-A73)에 배포하고, JNI/NDK로 Android 데모 앱을 구현하였습니다.
- Llama.cpp 추론 엔진의 메모리 할당 로직을 직접 분석·패치해 소형 T5 모델의 온디바이스 추론 메모리를 약 40% 절감하여 peak memory 30MB 이하, 15.30 ms/token를 달성하였습니다.
- 기존 표준 코덱(H.264 등)을 수정하지 않고 전단에 적용 가능한 딥러닝 기반 영상 전처리 DPC(Deep Pre-Coding) 모델 개발하였습니다. VMAF 기준으로 동일 화질 평균 BD-rate −23% 달성하였으며 YouTube 등 영상 플랫폼에서 VOD 업로드 시 재인코딩 · 압축 과정에서 발생하는 화질 열화를 방지합니다.
- TensorRT 활용하여 모델을 FFmpeg 커스텀 필터(C++/CUDA)에 통합, H.264 등 기보유 코덱과 연동되는 실시간 영상 처리 파이프라인 구축하였습니다. DPC+H.264 end-to-end 처리 속도는 1080p 기준 약 70 FPS를 달성하여 30fps급 VOD 콘텐츠의 실시간 처리가 가능합니다. (Intel Xeon Silver 4210R, RTX 3090 단일 GPU)
눈 앞의 사물을 AR-SCAN 하기 위한 Unseen Object Detection 모델 개발 업무를 수행했습니다.
-
Image-text pair 기반 class-agnostic object detection을 개발하였습니다. Point prompts 와 Top1(R@1) 알고리즘을 사용하여 검출된 다수 객체 중 사용자가 증강하길 원하는 단일 객체를 반환하도록 설계하였습니다. 해당 모델은 자체 in-house 테스트셋에서 mAR50-95 0.7814, Top1 98.10%를 달성하였으며, 이는 Google ML Kit(87.00%) 대비 +11%p 높은 수치입니다.
-
iOS/Android 데모 앱을 구현하고, 온디바이스 추론 모듈을 라이브러리로 패키징하여 배포하였습니다. CoreML/TFLite 기반 경량화·최적화로 iPhone 13 Pro 20ms, Galaxy S22 15ms를 달성하였습니다. 특히 Android에서는 uint8 quantization·NNAPI를 적용하여 추론 속도 150ms → 15ms(약 10×) 개선 및 발열 문제를 해결하였습니다. NNAPI가 지원하지 않는 multi-head attention의 BatchMatMul 제약은 모델 구조 재설계 & 학습으로 우회하였습니다.
-
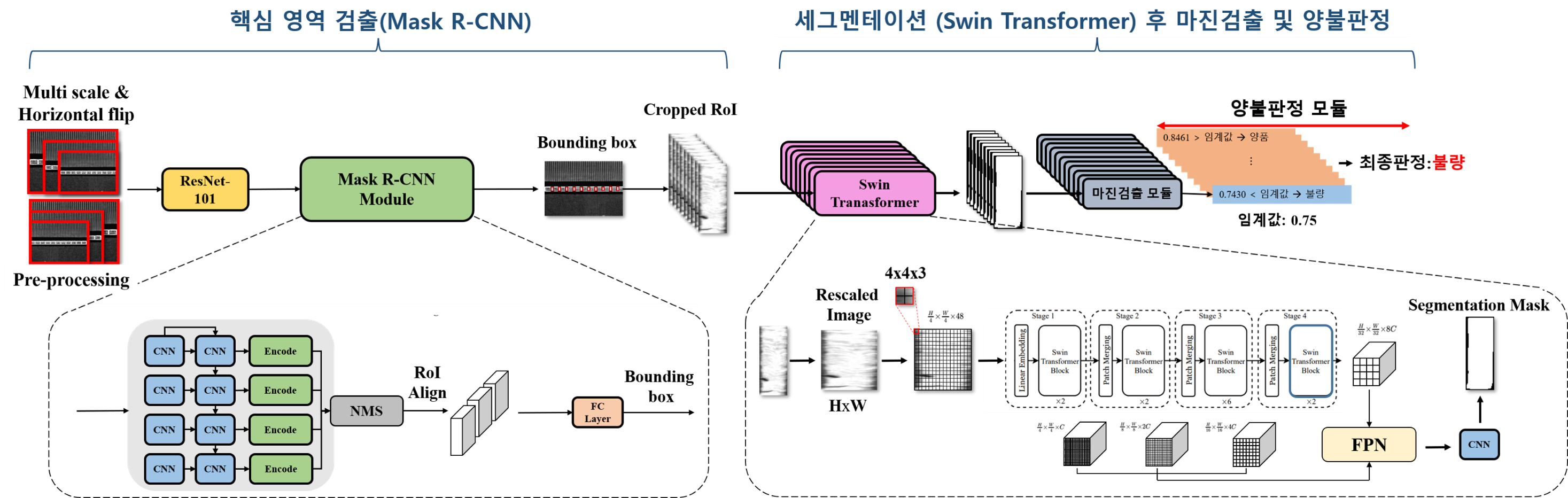
Goal: 사람이 목시로 수행하던 MLCC(Multi-Layer Ceramic Capacitor) 적층 양·불 검사 공정을 자동화하는 통합 검사 시스템 개발
-
Approach: 적층 검출 모델 · 적층 분할 모델 · 마진 검출 알고리즘을 개발하여 적층 이미지 → 최종 양·불 판정까지 end-to-end로 동작하는 웹 프로토타입 시스템 구축
-
Impact: 제안서 최종 양·불 검출 정확도 85% 대비 98%를 달성하여 삼성전기 공장에서 검사 인원 보조용으로 시험 가동
-
Papers: MLCC Lamination Alignment Inspection System using Deep Neural Network · Deep Learning-based MLCC Stacked Alignment Automatic Inspection System Using Independent Models
-
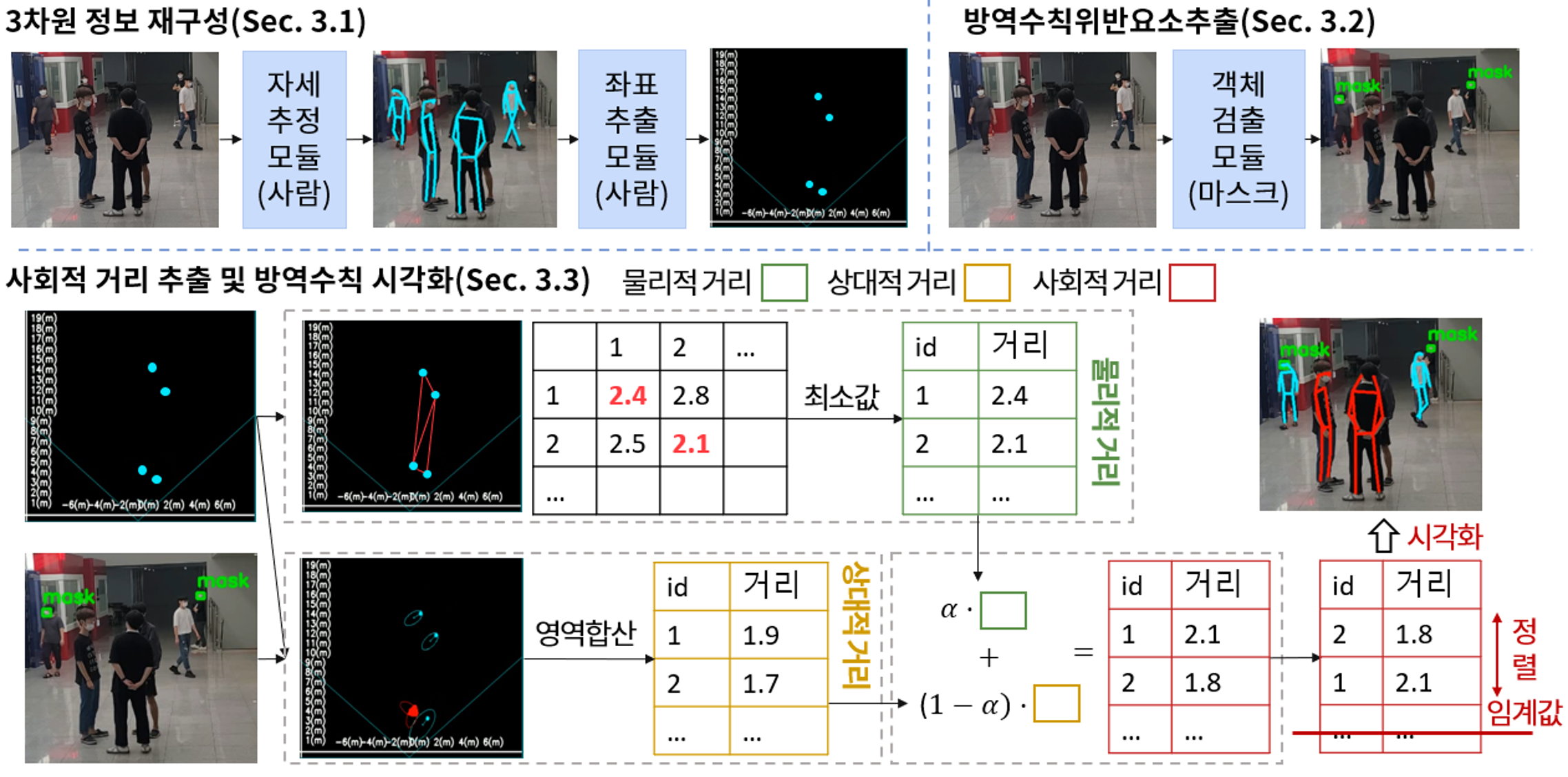
Goal: COVID-19 등 감염병 대응을 위해 마스크 착용 여부와 사회적 거리 측정을 통한 실시간 위험도 평가·방역대상 추적 시스템 개발
-
Approach: YOLOv5 + RetinaFace 기반 마스크 착용 탐지기를 개발, 자세 추정 기반 사회적 거리 측정 · 얼굴 마스크 검출 · 방역수칙 시각화 데모 구현
-
Impact: 마스크 검출 성능은 mAP50-95 0.76으로 baseline 대비 mAP 약 +2% 향상시킴
-
Paper: A study on the development of a system for monitoring quarantine rules using vision technology

-
Award: 위성 이미지 객체 검출 경진대회에서 1위, 방위사업청장상 수상
-
Approach: Patch 기반 multi-scale augmentation을 train·test에 모두 적용함 - FPN에 Libra R-CNN의 balanced feature pyramid를 추가함 - 당시 COCO object detection 1위 모델이었던 CBNet 백본을 직접 구현하여 public score 1위를 달성함
-
Papers: Deep Ensemble based Object Detection from Aerial Images · Uncertainty-based Deep Object Detection from Aerial Images
-
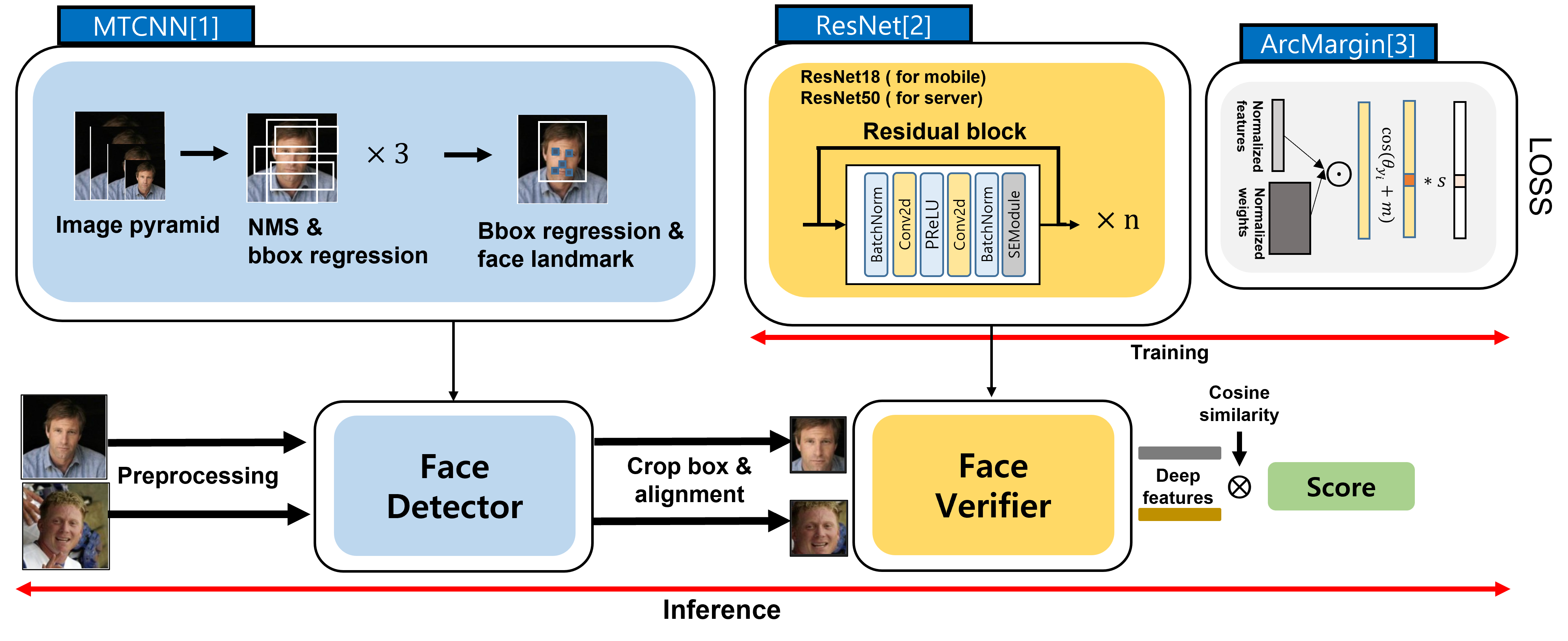
Goal: 한국인 얼굴 검출기·인식기 및 Android 앱 데모 개발
-
Approach: AI-Hub 한국인 얼굴 인식 데이터셋을 사용해 MTCNN 기반 얼굴 검출기와 ResNet + ArcFace 기반 얼굴 인식기를 개발하고 얼굴 검출 → 인식 후 사전에 갤러리에 저장된 얼굴과의 유사도로 동일인 여부를 판단하는 Android 앱 데모를 구현